AWSでVPC内にしかないリソースに対してローカルテストとかでサクッとアクセスしたい時
※追記:HAProxy構築した流れで色々試していたので必要だと思いこんでいましたが、HAProxy要らないですねこれ。
ちゃんと
とかを読んでもいないで理解もしていないのにググってコピペしてとりあえず出来たーとやるとこういう恥をかきますね。
ローカルマシンのMacからコード走らせたらエラー出まくってなんでだ・・・ってハマってから2日くらい色々試行錯誤していたメモ。
AWSのVPC内にしかリソースが無くNW的にグローバルからのアクセスが直接出来ない物に対してローカルのMacからどうやってアクセスするか、という流れ。
おおまかな流れとしてはめんどいが
- アクセスしたいリソースにアクセス出来るEC2インスタンスを起動
2. HAProxyを設定する - ローカルマシン側でHAProxyが起動しているインスタンスにSocks Proxyとしてsshで接続する
- 開発しているIDEに接続設定を入れる(今回はIntelliJ + Java)
という流れ。1は割愛。
HAProxy設定
とりあえず今回は用途的にTCP modeで設定。内容は雑にこんな感じ。
defaults
mode tcp
log global
option tcplog
option dontlognull
retries 3
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
maxconn 3000
frontend main *:80
default_backend backendApp
backend backendApp
balance roundrobin
server backendApp local.backendApp.example.com:8111 check
ローカルマシン側でHAProxyが起動しているインスタンスにローカルにSocks Proxyとしてsshで接続する
とりあえずこんな感じでSSHで接続する。
ssh -i .ssh/haproxy.pem -f -N -D localhost:1080 ec2-user@HAProxyマシンのグローバルIP
接続が完了したらローカルの1080ポートに接続したらHAProxyに接続出来るのでJavaでコマンドラインでやるなら
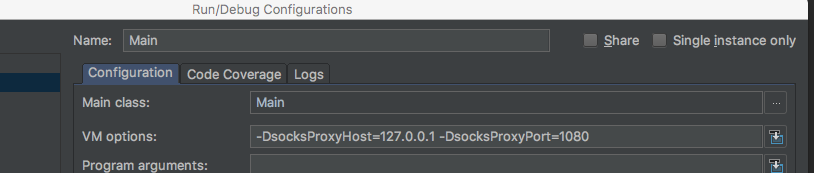
java -DsocksProxyHost=127.0.0.1 -DsocksProxyPort=1080 TestApp
こんな感じで起動したら無事HAProxy経由で接続が出来る。で、これをIntelliJで接続するにはRun -> Edit Configuration -> VM Optionに同じオプションを設定してあげればRun実行時も同じ事が出来る。
CircleCIとかでも多分同じ様な問題にあたって設定例を見つけたので多分外部CIサービスでも出来るとは思う。 ただ、IPアドレスのバッティングだけは気をつけてリソースを作成する必要があるとは思う。 gist.github.com
以上。
Cassandraにslow query logがマージされた様なので、どれだけ待望されていたのか勝手に簡単な解説をする。
題名のままです。
ついにCassandraにslow query logがVer 3.10でマージされた様です。
[CASSANDRA-12403] Slow query detecting - ASF JIRA
で、今までなぜこれが無かったのかというのと、どれだけ素晴らしいかというのを簡単に解説したいと思います。英語の部分はすごいニュアンスだけで書いていたり正確に仕様や歴史や経緯を把握している訳では無いのであくまでも傍から見ていてCassandraを運用した思い出を持っているだけの人が書いているという認識でお願いします。間違っていたらコメントで指摘下さい。もしくはもっとちゃんとした解説ブログ書いて頂ければ幸いです。
まずslow query log自体の要望は普通にありました。まあデータストア運用する人間からしても、実際にクエリを発行するアプリを書く人からしても当然ですよね。
[CASSANDRA-1305] Slow query log - ASF JIRA
ただこの時はパフォーマンスの問題やtrace logを実装するので、大半の問題は解決出来るのでは?という議論で完結している模様です。
[CASSANDRA-1123] Allow tracing query details - ASF JIRA
で、じゃあtrace logがslow query logの代替手段になるかと言うと、これはSQLで言うとEXPLAINに相当する機能となります。その為、「このクエリに問題がある」と分かっている時はCassandraのどのステージでどれだけ遅いのかが分かるのですが、「なんらかのパフォーマンス障害があった場合にどのクエリが問題だったか」という特定には不向きです。
で、月日は流れまたもJIRAに要望が上がっています。僕もこの辺の時期に運用に携わっていたので、このチケットは良く見た記憶があります。やっぱ欲しいですよね。
[CASSANDRA-6226] Slow query log - ASF JIRA
で、この時のDataStax co-founder and project chair for Apache Cassandra.であるJonathan Ellis氏の回答は凄くわかりやすく
「Tracing works fine at 0.1% or similar.(traceで同じような事出来るよ)」 注:trace logはsamplingでクエリの内何%かを拾い結果を出力する為、全てのクエリが等しく平均的に投げられていたら確かに彼の言うことも分かる。ただ、実際の運用では100万件のクエリの内数件のクエリのせいで著しくパフォーマンスに影響を及ぼしていた場合にサンプリングだと漏れてしまう懸念を僕も持っていたし、おそらくこのリクエストを書いた人も同じだったでしょう。
で、そうこうしているとクライアント側で使うJavaのdriver側でslow query logの機能が入った模様です。
https://datastax-oss.atlassian.net/browse/JAVA-646
とりあえずこれで安心ですね(ニッコリ ただ、このドライバを使わないと結局自分でslow query log相当を実装必要があるのと、今取りたい!みたいになった時にアプリ側全部で設定を動的にONに出来るようにしないといけない気がします。この辺は使った事が無いので想像で書いています。あとはNWの影響を受けた場合に「クエリが悪いのかそれとも他のレイヤの問題でレスポンスが遅くなったのか」も切り分けがやっぱり微妙になるので、Cassandraノード側でslow query logはやっぱり欲しいですよね。
で、冒頭に書いたJIRAに行き着く訳です。
JIRAの中を見てみるとShogo Hoshiiさんという方がコミットしており、おそらく
にて発表をされたヤフー株式会社の星井 祥吾さんであると思います(間違っていたらほんとすみません。)非常にタフなやりとりがCommentsからも垣間見れます。運用していた時期にたまたまカンファレンスで発表する機会を貰えた時に「slow query log欲しいー」ってだけ言って結局正式なrequestやpatchも書かなかった僕とは大違いですね。
最後に念のため書いておくと、このブログを書くためにググってみたらDSEではVer 4.5にてslow query logの機能は実装されていた模様です。
ただし、Cassandra本体に無い機能だという事からおそらくDSE内でなんらかのコンポーネントを組み合わせて実現したのではと推測しています。もしくは独自パッチでしょうか。
という訳で実際に読み返すと推測とかニュアンスばっかりで解説と言えるかどうか微妙なエントリですが、この機能は自分も運用時に待望していた機能でもありましたので、今Cassandraを運用している方はリリースされたらアップデートをする事により、より素晴らしいCassandra運用ライフを送れるのではないでしょうか。
全然経緯も仕様も違うぞ!!デマ流すんじゃねぇ!!!!という場合は是非ちゃんとした解説を書いて頂き僕に教えて頂ければ幸いです・・・。
Splatoonをより楽しくプレイする為に買ったもの
前にブログ書いたのが半年くらい前なのに全く技術情報では無いですが一応仕事はちゃんとしていました。きっと。
2015年の俺ベスト・バイアイテムとして名高いSplatoonですが、2016年ベスト・バイの候補にもなっているレベルで今も非常に楽しくプレイしています。ちなみにウデマエは半年くらいやってSなので人並みレベルより多分下手な方だと思う・・・。きっと皆様も楽しくプレイし、、時にはパッドを投げ、時にはパッドを割り、時には負け試合で味方の戦犯探しに勤しんでいる方もいるかと思います。そんな僕ですがSplatoonをやるためにWii Uを買いその後もちょこちょこ色んな物を買いましたので備忘録とナレッジの共有をさせて頂きます。
ElgatoGame Capture HD60
Game Capture HD60 | elgato.com
何をするものかと言うとWii UのHDMI出力をキャプチャしPCに動画として保存出来るデバイスです。要はキャプチャボード。これの良い所としては
デバイス側でエンコードするのでPCの負担が少ない
HDMI信号がパススルーでTVに出力されるので(少なくとも僕レベルでは)遅延が無い。
Macにも管理アプリが対応していてなおかつYoutube、Twitchなどにはボタン一発で投稿出来る機能とRTMPでの配信にも対応
しています。但しRTMPのビットレートが最低でも500kbpsとなっておりニコ生は直接対応出来ず。残念。あとキャプチャした動画の簡単な編集も可能なので、これで自分のプレイ動画を見て「うわ・・・なんでこいつこんな所で突っ込んでいるんだろ・・・」「いや・・・そこ塗れよ・・・」などを冷静に見る事が出来ます。もちろんたまたま上手く行った試合の動画を見て「俺やっぱ上手いじゃん!」って悦に浸る事も可能です。 これを買って自分のプレイ見るようになったからちょっとは上達した気もします。あとは単純にタッグマッチとかプラベやった時の動画を共有出来るのでおもしろ珍プレーを残す事も出来ますね。
あと、管理アプリを起動しておくとドライブレコーダーの様に自動的に録画をしておき、あとで「いい試合だったわー動画にしよう!」という時にキャプチャしたい場面を選択して保存する事が可能なので毎回録画設定してからプレイする、みたいなのをしなくても良いところが便利です。
注意点としては2015年MBPを使っていますが、1080p フルHDを60fpsでキャプチャし更に管理アプリでプレビューした上でストリーミングするのはさすがにきつくCPUがパツるので、今は720p 60fpsくらいでプレビューしない状態でキャプチャしています。そうすると4コアのCPU使用率がだいたい30%くらいで他の作業しながらでも快適でした。 あとIkaLogが動きません…。
だいたいこんな感じで個人で見る分には十分過ぎるくらい綺麗。
belkin MixIt UPシリーズ マルチイヤホンスプリッター ロックスター
何をするものかというと、複数の音声入力をmixして複数のデバイスに出力出来るものです。各ポートは自動で音声の入力、出力を判断してくれるのでケーブルさすだけでOKというお手軽な製品でした。タッグマッチやプラベをやる時にskypeでボイチャしながらSplatoonをしたいんですが、そうなるとPCの音声を片耳ヘッドホンで聞くことになりゲームの音が若干聞こえづらいんですよね。なので、これで音声をmixすることで1つのヘッドホンでPCからの音声とWii Uの音声を混ぜて聞くことができました。もちろんミキサーを使えば同じ事は出来るんですがこの為にミキサー買うのは高かったのと邪魔になるので躊躇していましたが、これは1000円台後半という事もありお手軽でした。注意点としては各音声入力はそれぞれのデバイス毎に調整をする必要があるのと複数の音声が入ると出力時にそれぞれのボリュームが小さくなるので多少の調整が必要になります。まあ普通に音声ボリューム調整すれば済むレベルです。あとWii Uパッドからの音声出力だと若干ボリュームが小さかったのでTV側の音声をこれに繋げています。
このようにSplatoonを買い、更に快適にプレイするためのデバイス購入にも繋がる事で日本経済にも貢献出来たのでほんと良いゲームですね。最後にシオカライブ2016の動画でお別れです。イカヨロシクー。
間違った技術ブログを書いた時に如何に修正するか
考え方やその時の流行のアーキテクチャとかもあるのでそういった物はそれでいいですが、明らかに間違えた事を書いて出来ない!とか載せてしまう時があります。にんげんだもの。 ただ、それを放置する、削除するとかはあまり良くないアプローチだと考えています。理由はそれを読んで真似してしまった人が一人でもいるかもしれない、同じ間違いをする人がいるかもしれない時にその間違いは良い勉強になる、などなど。 最も大きな理由は「間違いを指摘してくれた人に対してちゃんと敬意を払って修正する」が間違えた記事を書いた事に対する責任だと僕は考えています。その為もし僕が不完全なブログを書いて「ちげーだろ。もっと勉強しろ」と言われ確認し自分の間違いに気づいたら顔を真赤にして枕に顔をうずめてバタバタしたり酒を飲んで憂さを晴らすのではなく
- まず冒頭に間違っていたことを素直に認める
- 何が間違っていたかをちゃんと正確に記載する
- 原文中に追記するなら、わかりやすく追記と分かるように「ここが間違いでした。理由はこれをしていなかった。」などと書く
ドヤ顔で「間違えやすいからみんなも気をつけよう。」と書く
辺りをする事でもし読んでしまった人が改めて情報ソースとして読んだ時にも間違いを共有できるのと、自分が読み返した時に「同じ間違いしないようにしよう///」と思えるので間違いも記録として残しておくべきだと考えています。 もちろん誤りの内容にもより指摘した人が「これは削除すべきだ!!」ってなったらこの限りでは無いですが。
その為僕は「あー出来ないなーこんなエラーログ出ましたわ」ってブログ書くと1時間後に「追記:正しい設定教えてもらいました。本当は出来ましたごめんなさい。」みたいな事をいっぱい書いています。
embulk-input-dynamodbを使ってみました
※このブログは所属している組織の意見などは全く含まれてない個人の意見です。技術的な問題などがあっても悪いのぼくです。
DynamoDB + Hiveでゴニョゴニョ試したりしていたのですが、Hiveを全くチューニングせず試していた為結構遅いので
※nginxのアクセスログがDynamoDBに入っていると思ってください。 SELECT COUNT(id) from hoge WHERE status = 504
みたいなちょっとテストデータを確認するようなクエリを投げてもそこそこ時間が掛かってしまい何か楽できないかなーとTwitterでつぶやいていると
@oranie @repeatedly embulk-input-dynamodb の出番のようですね
— FURUHASHI Sadayuki (@frsyuki) June 30, 2015と @frsyuki先生からリプライを頂き今まで情報は見ていたけど触っていなかったのでembulkを試してみました。
で、表題のembulk-input-dynamodbを使ってみたんですがまだ開発中だったらしくscanが最大1MBの1回で終わってしまう問題があったんですがこれもTwitterでつぶやいたら開発者の@Lulichnさんが拾ってくれてすぐに修正してくれました。ありがたやありがたや。で、追加で僕もちょっとだけpull req投げさせて貰いこれで
・1回のscanの読み取り回数(最大1MBなのはDynamoDBのscan仕様な為変わらず。1000000000とか書いても1MBの仕様に当たるとそれ以上読まずに次のscanが必要です。)
・embulkで読み取る最大レコード数(100とか書けば最大100レコード出力で終わり。)
・IAM role対応
が出来るようになり、filter部分に条件式を書いて標準出力させればちょっとした確認がすぐに出来るようになりました。
以下簡単な設定の流れ
DynamoDBにテストデータを入れる。
とりあえずここは面倒くさいのでnginxのログをfluent-plugin-dynamodbで入れました。一点補足として動作テストしたEC2インスタンスにはIAM roleが設定されているのでACCESS KEYなどは設定していません。
nginxのログフォーマットは
log_format ltsv 'time:$time_iso8601\t'
'remote_addr:$remote_addr\t'
'request_method:$request_method\t'
'request_length:$request_length\t'
'request_uri:$request_uri\t'
'uri:$uri\t'
'query_string:$query_string\t'
'status:$status\t'
'bytes_sent:$bytes_sent\t'
'body_bytes_sent:$body_bytes_sent\t'
'referer:$http_referer\t'
'useragent:$http_user_agent\t'
'forwardedfor:$http_x_forwarded_for\t'
'request_time:$request_time\t'
'upstream_response_time:$upstream_response_time';
です。fluentdは
<source>
type tail
format ltsv
tag nginx.access
path /var/log/nginx/access.log
pos_file /var/log/td-agent/buffer/access.log.pos
</source>
<match *.**>
type copy
<store>
type dynamodb
dynamo_db_endpoint dynamodb.ap-northeast-1.amazonaws.com
dynamo_db_table access_log
</store>
</match>
こんなレベルです。
embulkインストール
を読んで環境に合わせてインストールします。
プラグインインストール
embulk gem install embulk-input-dynamodb
で完了。
config設定
ここも稼働させるEC2インスタンスにはIAM roleが設定されているのでcredentials情報などは記載しません。
in:
type: dynamodb
table: access_log_range
region: ap-northeast-1
scan_limit: 10000
record_limit: 10
columns:
- {name: time, type: string}
- {name: request_uri, type: string}
- {name: status, type: string}
out:
type: stdout
embulk実行
ここまでやったら
[oranie@ip-172-31-6-145 embulk]$ embulk run ./dynamodb.yml
2015-07-01 04:36:50.963 +0000: Embulk v0.6.15
2015-07-01 04:36:52.474 +0000 [INFO] (transaction): Loaded plugin embulk-input-dynamodb (0.0.2)
2015-07-01 04:36:52.523 +0000 [INFO] (transaction): {done: 0 / 1, running: 0}
2015-06-27T07:43:34Z,/,200
2015-06-16T08:38:47Z,/notfound,404
2015-06-18T22:46:35Z,/,200
2015-06-17T08:05:34Z,/,200
2015-06-16T08:38:46Z,/notfound,404
2015-06-19T00:32:04Z,/,200
2015-06-26T16:44:35Z,/,200
2015-06-16T08:38:49Z,/notfound,404
2015-06-27T03:49:35Z,/,200
2015-06-18T21:18:04Z,/,200
2015-07-01 04:36:53.598 +0000 [INFO] (transaction): {done: 1 / 1, running: 0}
2015-07-01 04:36:53.610 +0000 [INFO] (main): Committed.
2015-07-01 04:36:53.610 +0000 [INFO] (main): Next config diff: {"in":{},"out":{}}
[oranie@ip-172-31-6-145 embulk]$
こんな感じでデータが出力されます。
おしまい
【チラ裏】無職になって1ヶ月が経ちました。
有給消化を入れると2ヶ月くらい地元の北海道で遊んだり引っ越ししたり酒飲んだりしました(∩´∀`)∩ワーイ
で、さすがに引っ越ししたりでお金が無くなり生きていけないので働く事になりました。職場はAWS(アマゾン データサービス ジャパン)にSolution Architectとしてジョインしました。
真面目な話をちょっと書くと今までは一般ユーザーにサービスを提供する側の事業者(いわゆるBtoC)で働いている事が多く、正直退職を考えた時期は「自分が興味を持てるサービスをしている会社さんの話が聞けたら良いなー」という感じで、クラウド事業者に行こうとは正直選択肢に出てこなかった感じもありました。ただ、ひょんなことからお話を聞かせて頂き、最近では
こんなイベントもあり、逆に言うとクラウド事業者で働くというのはいわゆる「インフラレイヤ」でやってきたエンジニアにとってはスタンダードなキャリアなのかな?というのもありました。という訳で「一度はクラウド事業者の経験を積むことは例えクビになっても今後の役に立つのでは」と思いエントリしありがたくジョインする流れとなりました。
今までAWSについては小さな規模の物をクラスメソッドさんのブログ
を見たりしてちょろちょろ試してなんとか動かしていたり・・・という感じなので、まずは早くAWSを理解し今使っている人やこれから使おうかと検討している人に少しでも役に立てる様に頑張ります。今はAWSユーザーとして僕より使い込んでいる人が凄く多いので、まずは「中の人」と胸を張れるレベルにならないと、とプレッシャーで酒の量が増えそうです。
最後に今後も与太話をブログやTwitterで書くかもしれませんが、完全に「所属する組織の意見ではありません」ので宜しくお願い致します。
【チラ裏】近況報告
皆様サガシリーズはご存知でしょうか。昨年はサガ25周年というめでたい年でした。特にロマサガシリーズ、サガフロンティア2が好きで「ついに最低でもロマサガ2、3のリメイク来るか・・・」と待ち焦がれていた時に「ロマンシング佐賀」が発表され
マジでこれが25周年にふさわしいコンテンツだと思っているスクエニに期待をする方が馬鹿だったんや…
— oranie (@oranie) 2014, 2月 19
という絶望に打ちひしがれたツイートをしていました。
そこから1年弱。ついに「SAGA2015」が発表されました。はじめは半信半疑でした。
えっ・・・SAGA2015って・・・本当に新作なの・・・?
— oranie (@oranie) 2014, 12月 14
今年一年スクエニに裏切られてきたから、未だに信じられない。何か罠がある気がする…。
— oranie (@oranie) 2014, 12月 14
と疑っていましたが、ついにちゃんとプレスリリースも公開され鋭意開発中との事。
「サガ」シリーズ25周年 新作「SAGA2015(仮称)」for PlayStation Vitaなど 新タイトル、新イベントを発表 | SQUARE ENIX
位置づけとしては「ロマサガ4」と言っても良いタイトルという情報を聞き、これは僕も本気を出さないといけないと思いました。いつリリースされても全力を尽くせる体制を作る必要がある。そう確信しました。

という訳で無駄な前フリ長かったですが、サイバーエージェントを退職しました。本日最終出社で今後有給消化を行い完了後晴れてニートとなります。これでSAGA2015がいつ来ても大丈夫。いつでも本気出せる。
真面目な話をするとまあテンプレに近くなってしまいますが、何か凄くネガティブな理由がある訳でもなくて、7年ほど勤めた環境をそろそろ変えてみるかというのと、この半年くらいは僕レベルで中途半端な何でも屋さん感があったがもう少しレイヤを絞った方が良いかな、という考えから退職を決意しました。もちろん普通に仕事していて怒ったりブーブー言う事もありましたが、それはどこで働いても出るレベルの奴です。居酒屋の酒の肴程度です。
今まで色んなプロジェクトにアサインして貰い、特にこの二年間くらいはCassandraなどの分散データストアに触る機会を貰い、Cassandra Summit JPNでスピーカーをさせて頂く機会が貰えるまでになれたのは確実にサイバーエージェントという環境にいたからだと思っています。もちろん、Cassandra summit JPNに限らず他の勉強会やカンファレンスでLTやスピーカーなどを出来たのは環境に限らず多くの社内、社外のエンジニアの方のおかげで成長させて貰ったのもあります。昨日デスクに積んでいる技術本を持って帰っていると「あー俺本当に明後日からここに来なくなるんだ。これから何しよう・・・。」って思う寂しさもありました。
一緒に仕事をさせて貰ったエンジニアのみんなは本当にレベルが高くて、年齢関係なく尊敬しているメンバーばかりです。つい先日も同僚が書いた本を頂いて書評的なやつを書かせて頂きましたが
「HBase徹底入門」を読みました。 - oranie's blog
や
第66回 リアルタイムメッセージ共有を実現する社内SaaS基盤:サイバーエージェントを支える技術者たち|gihyo.jp … 技術評論社
や
テックレポート - TechReport | 株式会社サイバーエージェント
など凄い事やっている人が一杯いるので刺激を貰いました。これからの活躍を心から応援しています。本当にみなさんのおかげで頑張ってこれました。本当にありがとうございました。期待に応えられなかった事も多かったと思います。恩返しも出来ないままで去ることになってしまった人もいてそこが一番の心残りです。またどこか別の機会に一緒に仕事を出来る事になれば宜しくお願い致します。

最後に流行のAmazonウィッシュリストを公開します。「おれのさいきょうのウィッシュリスト」なので、見て楽しんで頂ければ幸いです。ポチると一瞬でクレジットカードが止まると思いますのでほんとやめろよ!押すなよ!
という訳で次の職場はこれからゆっくり探す感じになります。お前ごときがどこかの怪人大物みたいな真似してんじゃねーよ!って叱られそうですが、ここ最近は多少不摂生な生活を送っていた事もあり、この期間に運動したりなど改めて体調を整えたいとも考えているので少し長めの休みも辞さない感じで考えております。もちろん早めに決まれば普通に有給消化後に晴れて転職となります。
長文失礼しました。
おしまい。